【OpenAI】OpenAI API学习笔记
更新中……
官网教程:https://platform.openai.com/docs/quickstart
获得 OpenAI API Key
获得 OpenAI 账号
若之前使用过ChatGPT,ChatGPT的账号就是OpenAI账号,直接使用即可。
若没有,则可以在此处注册:https://platform.openai.com/signup
由于对国内封锁的缘故,国内注册可能较为复杂。网上有众多注册教程,这里不再赘述。
嫌麻烦上某宝买号也可;或者直接买个有额度的 API Key。
获得 OpenAI API Key
登录后,鼠标移动到页面左侧,会有一个弹出的侧边栏。
点击侧边栏中的“API Keys”进入 API Keys 页面。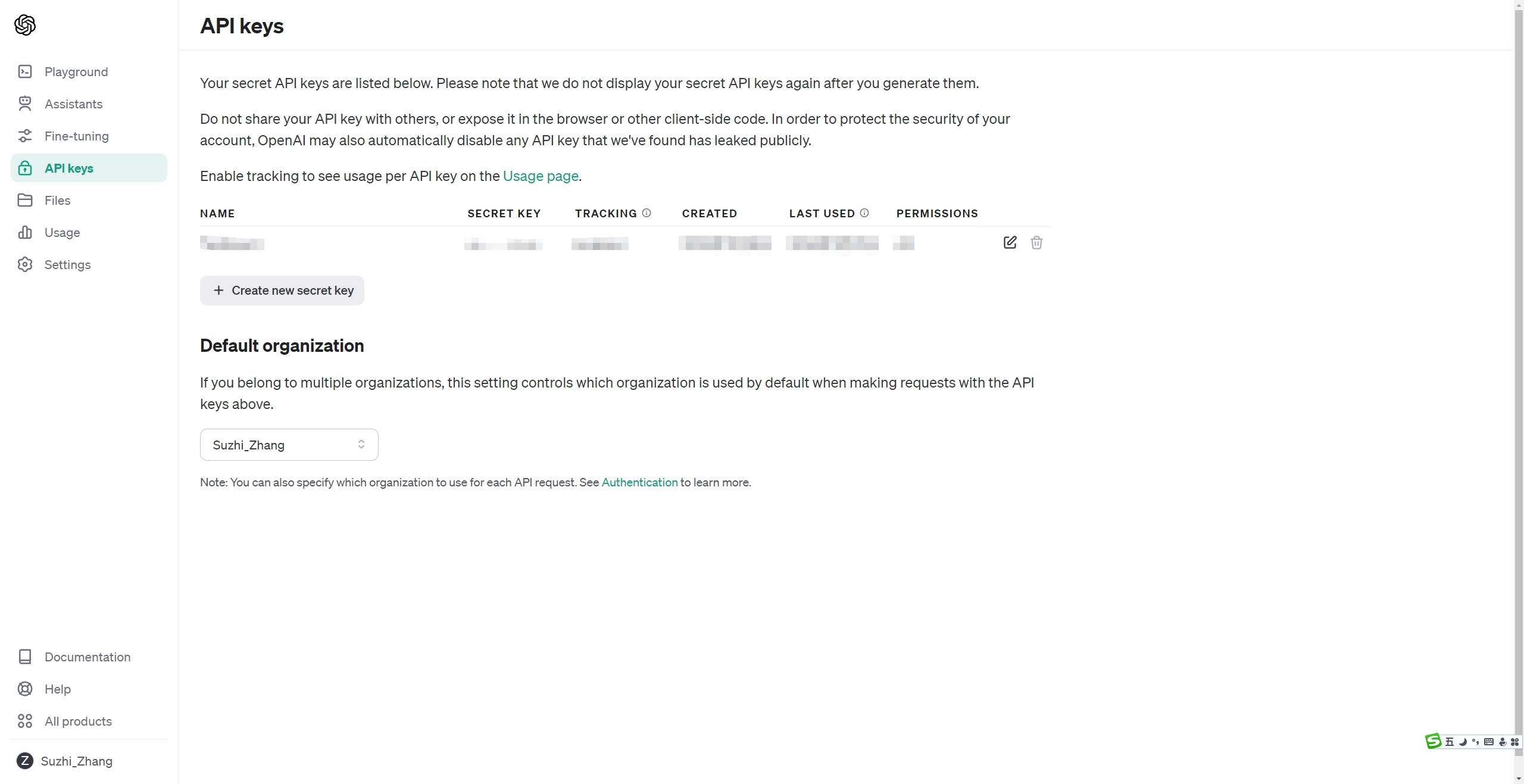
在这里可以管理(创建、删除等)我们所有的 API Key。
点击“Create new secret key”创建新 API Key,进行命名,点击确定即可。
现在会弹出一个对话框,其中有我们创建的Key,一定要立马把这个 Key 保存下来,这个对话框关闭后就再也没有办法看到这个 Key 了。
保存完后点击Done,就可以在该页面看到新创建的 API Key 了。
获取 API 使用额度
额度查询
点击侧边栏中的“Usage”进入使用页面。
该页面左侧显示了每天的花费,右侧则显示了额度。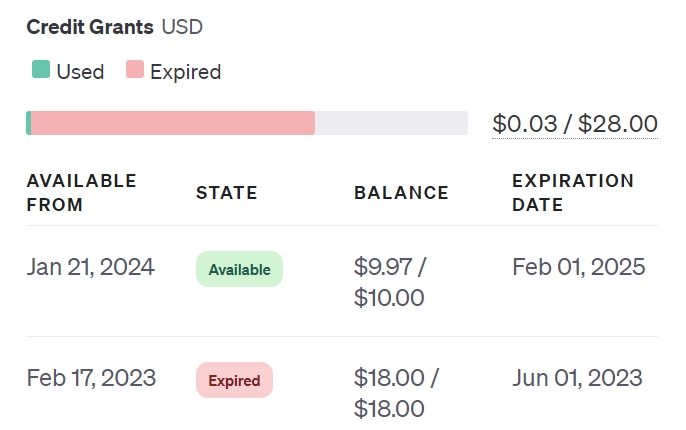
在右侧 Credit Grants 区域,分为3种颜色:灰(未使用)、绿(已使用)、红(已过期)。只有还有额度处于未使用状态(灰色状态)时,才使用 Key 成功调用 API。
额度充值
点击侧边栏中的“Setting”下的“Billing”进入账单页面。
在这个页面中可以管理充值相关事项。
要充值首先要添加一种付款方式,点击 Payment methods 就可以管理自己的支付方式了。
还是由于封锁的原因,国内的 visa 卡可能无法使用。这个比较难搞,可以使用国外的卡,或者也可以使用网络的卡,这里我使用的是这个卡:https://bewildcard.com/i/SUZHE ,付款挺方便,不过开卡费略高 $15.99,充值有手续费 3.5%,看需求使用就好。
添加了支付方式后,回到 Overview 页面点击 Add to credit balance 就可以进行充值。充值完后回到 Usage 页面就可以看到可用额度的变化。
Python使用测试
配制 Python
Python版本要3.7.1以上。
这里我为了方便使用 Anaconda 创建了一个虚拟环境。
如果不使用 Anaconda,可以看这个教程:https://docs.python.org/3/tutorial/venv.html
安装 OpenAI 库
Anaconda
安装 OpenAI 库

pip
1
pip install --upgrade openai

设置你的 API Key
OpenAI 默认会去环境变量中找“OPENAI_API_KEY”,使用其作为 OpenAI Key。因此有以下两种设置 OpenAI Key的方法:
为所有项目设置
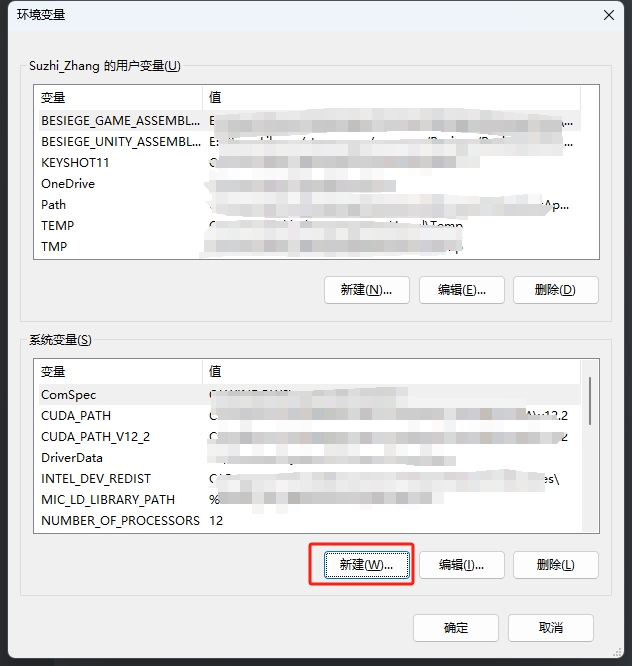
在系统环境变量中的系统变量中添加OPENAI_API_KEY(按Win键搜索环境变量就可以打开这个页面);
添加完成后,可以打开cmd,用 echo %OPENAI_API_KEY% 检查是否设置成功。
1
2
3from openai import OpenAI
client = OpenAI()为单个项目设置
在项目文凭夹里创建.env文件(若要用git进行管理,要用gitignore忽略),输入 OPENAI_API_KEY=(你的Key)
1
2# Once you add your API key below, make sure to not share it with anyone! The API key should remain private.
OPENAI_API_KEY=abc123然后在使用前加载一下env文件(这里我使用的是dotenv库):
1
2
3
4
5
6import dotenv
from openai import OpenAI
dotenv.load_dotenv()
client = OpenAI()
进行运行测试,没有报错即可。
OpenAI 默认会去环境变量中找“OPENAI_API_KEY”,若要使用其它环境变量名,可以:
1 | client = OpenAI( |
发送请求测试
来个最简单的 gpt-3.5 chat 请求
1 | import os |
现在在Usage页面就可以看到我们这次请求的花费、token数量等信息了(可能有延迟)。
图像请求
功能介绍(Python为例)
Text Generation
官方教程:https://platform.openai.com/docs/guides/text-generation
可以理解语言(GPT-4也可以理解图像),并返回文字。
请求
1 | response = client.chat.completions.create( |
主要的输入是messages,是一个message对象的列表。message对象由role(system, user或assistant)和content组成。一般来说,对话都是由一个system信息开头,然后跟着数个user或assistent信息。
- system(可选):用于设置AI的行为,如个性或对话过程中的行为指示;
- user:AI要回应的信息;
- assitent:之前AI回复的信息,也可以自己写,以给AI预期输出的参考;
其它参数:
- model:https://platform.openai.com/docs/models
- n:int或null,回复数量,默认为1;
- response_format:object,见下文JSON;
- seed:int或null,种子;
- stop:string, array或null,停止条件;
- stream:布尔或null,是否使用流输出,见下文Stream;
- temperature:数字或null,0-2,越大越随机;
回复
官方文档:https://platform.openai.com/docs/api-reference/chat/object
1 | { |
提取回复:
1 | response['choices'][0]['message']['content'] |
每个回复其中都有finish_reason:
- stop:API返回信息已完成,或触发了stop参数传入的stop sequence;
- length:到达了max_token参数或模型的token限制;
- tool_call:模型决定调用工具;
- content_filter:由于内容过滤器,内容被隐藏;
- null:还没完成;
Image Input
GPT-4的vision版本可以理解图像。
在user massage的content中,添加type为image_url的图像url即可。
1 | response = client.chat.completions.create( |
这里传入的图像是:

输出是
1 | 这张图片展示了一个现代化城市的黄昏景象。天边的云朵被夕阳映照得呈现出橙色与蓝色的层次,远处的天空还带有一抹粉红。 |
可以同时添加多个图像。
image_url中的detail参数可以控制模型处理图像的方式。
- 默认为auto;
- low时会使用512*512的低质量图像(65 token);
- high会先让模型看512的低质量图像,然后将图像分成多个512的正方形图像逐一查看(每个129 token);
high时图像大小要小于768*2000
其它限制
- 图像格式:PNG, JPEG, WEBP, 不动的GIF;
- 大小限制:单张20MB;
- 模型无法理解图像的元信息;
Stream
如果想要像ChatGPT一样逐字输出回复,将stream参数设置为true即可(例子)。
1 | response = client.chat.completions.create( |
回复将以chunk对象:
官方文档:https://platform.openai.com/docs/api-reference/chat/streaming
1 | { |
JSON
若想让模型永远输出JSON对象,可以将response_format设置为{ “type”: “json_object” }。
- 要使用JSON模式,一定要在Prompt中指示模型生成JSON(比如在system信息中)。
- 在使用输出的JSON前先检查finish_reason,若是length则JSON结果是被剪裁的,不能使用。
Image Generation
其它功能
![]()
- 微信
- 支付宝